DRF插件 Restful API设计最佳实践 REST(Representational State Transfer),表现层状态转移。
表现层是资源的表现层,对于网络中的资源就需要URI(Uniform Resource Identifier)来指向。REST指的 是资源的状态变化。
注意:RESTFul没有标准
协议 使用HTTP或者HTTPS。对外若有安全性要求,可以使用HTTPS。但是内部服务间调用可以使用HTTP或 HTTPS。
HTTP方法 HTTP请求中的方法表示执行的动作
常用方法(动词)
说明
GET
获取资源
POST
创建新的资源
PUT
更新资源
PATCH
部分更新资源
DELETE
删除资源
使用名词 URL指向资源 ,在URL路径的描述中,只需要出现名词,而不要出现动词。动词由HTTP方法提供。 不要单复数混用,建议名词使用复数。
Restful的核心是资源,URL应该指向资源,所以应该是使用名称表达,而不是动词表达。
常用方法(动词)
说明
GET
/posts
返回所有文章
GET
/posts/10
返回id为10的文章
POST
/posts
创建新的文章
PUT
/posts/10
更新id为10的文章
PATCH
/posts/10
删除id为10的文章
DELETE
/posts/10
部分更新id为10的文章数据
不要出现下面的访问资源的路径
1 2 3 4 /getAllPosts /addPost /updatePost /delPost 上面URL中动作和资源混在一起,不好
GET方法只是获取资源,而不是改变资源状态。改变资源请使用POST、PUT、DELETE等方法。 例如,使用 就可以获取资源了,但是却使用GET /post/10/del或 GET /post/10/?v=10,本意是想删除。但这样不好,GET方法请求只为获取资源,不要改变资源状态。
子资源的访问
方法
路径Endpoint
说明
GET
/posts/10/authors
返回id为10的文章的所有作者
POST
/posts/10/authors/8
返回id为10的文章的作者中id为8的
集合功能 过滤 Filtering
指定过滤条件 GET /posts?tag=python
排序 Sorting
指定排序条件。有很多种设计风格,例如使用+表示asc,-表示desc。GET /posts?sort=+title,-id或GET /posts?sort=title_asc,id_desc
分页 Pagination
一般情况下,查询返回的记录数非常多,必须分页。GET /posts?page=5&size=20
状态码 使用HTTP响应的状态码表示动作的成功与否。
2XX表示用户请求被服务器端成功的处理
4XX表示用户请求的错误
5XX表示服务器端出错了
Status Code
说明
Method
说明
200
OK
GET
成功获取资源
201
CREATED
POST、PUT、PATCH
成功创建或修改
204
NO CONTENT
DELETE
成功删除资源
400
Bad Request
ALL
请求中有错误,例如 GET时参数有问题 PUT时提交的数据错误等
401
Unauthorized
ALL
权限未通过认证
403
Forbidden
ALL
有无权限都禁止访问该资源
404
Not Found
ALL
请求的资源不存在
500
Internal Server Error
ALL
服务器端错误
详细状态码参考:https://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
错误处理 在Restful API设计中,错误处理也非常重要。单单从状态码中无法详尽描述错误的信息。
返回消息
1 2 3 { "error" :"User Not Found" }
从错误消息中了解到错误号、错误信息、错误描述等信息。甚至更详细的信息可以通过code查阅文档
1 2 3 4 5 { "code" :10056 , "message" :"Invalid ID" , "description" :"More details" : }
code 为 0 表示无错误。非0表示有错误,就要看message中的错误描述了。
版本 在较大项目开发时,由于业务升级,需要对接口调用做出改动,例如请求参数、返回状态码、json数据 发生变化等。如果使用同一套接口,在原有接口上直接修改会导致原有调用者调用出问题。解决方法:
完全兼容原有接口,虽然这样做可以,但是很难做到所有接口的完全兼容设计。实在不行的,老的 接口保留不动,建立新的API接口以供调用
对已经发布使用的接口规定版本号访问。新增的、改进的、删除的API重新发布新的版本。项目开 发时,指定版本和接口即可。老项目可以不必升级到这个新版本。
强烈要求使用版本,版本号使用简单数字,例如v2。
2种风格
返回结果
方法
路径
说明
GET
/posts
返回所有文章的列表
GET
/posts/10
返回id为10的文章对象
POST
/posts
创建新的文章并返回这个对象
PUT
/posts/10
更新id为10的文章并返回这个对象
DELETE
/posts/10
删除id为10的文章返回一个空对象
PATCH
/posts/10
部分更新id为10的文章数据并返回这个对象
返回数据一律采用JSON格式。
视图函数 视图函数(Function-based View),即视图功能由函数实现。
JSON响应 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from django.http import HttpRequest, HttpResponse, JsonResponsedef test_index (request:HttpRequest) : data = [1 , 2 , 3 ] return JsonResponse(data) TypeError: In order to allow non-dict objects to be serialized set the safe parameter to False . 。意思是,safe参数为False 才可使用非字典数据,所以,除非有必要,否则还是使用字典 from django.http import HttpRequest, HttpResponse, JsonResponsedef test_index (request:HttpRequest) : data = {'a' :100 , 'b' :'abc' } return JsonResponse(data)
请求方法限制装饰器 如果需要对请求方法限制,例如只允许GET方法请求怎么办?当然可以自己判断,也可以使用Django提供的装饰器函数。
1 2 3 4 5 6 7 8 9 from django.http import HttpRequest, HttpResponse, JsonResponsefrom django.views.decorators.http import require_http_methods, require_GET, require_POST@require_POST def test_index (request:HttpRequest) : data = {'a' :100 , 'b' :'abc' } return JsonResponse(data)
测试过程中,当使用不被允许的方法请求时,返回405状态码,表示 Method Not Allowed
装饰完后, test_index就是新的视图函数,装饰器内部的 inner函数 。这类似于在装饰器一章学过的logger装饰器。
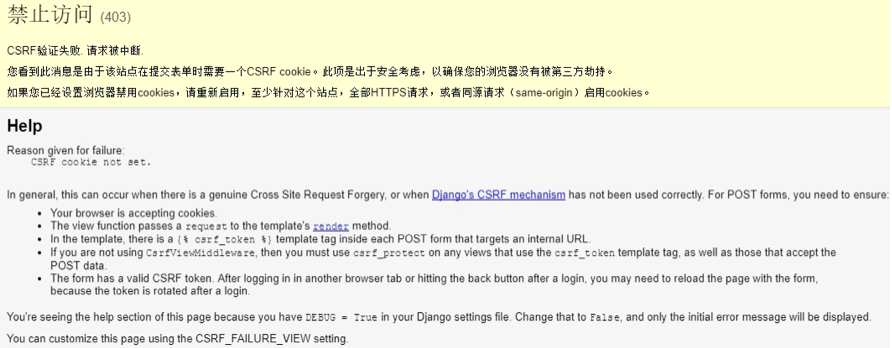
CSRF处理 在Post数据的时候,发现出现了下面的提示
原因:默认 Django CsrfViewMiddleware中间件会对所有 POST方法提交的信息做 CSRF校验 。
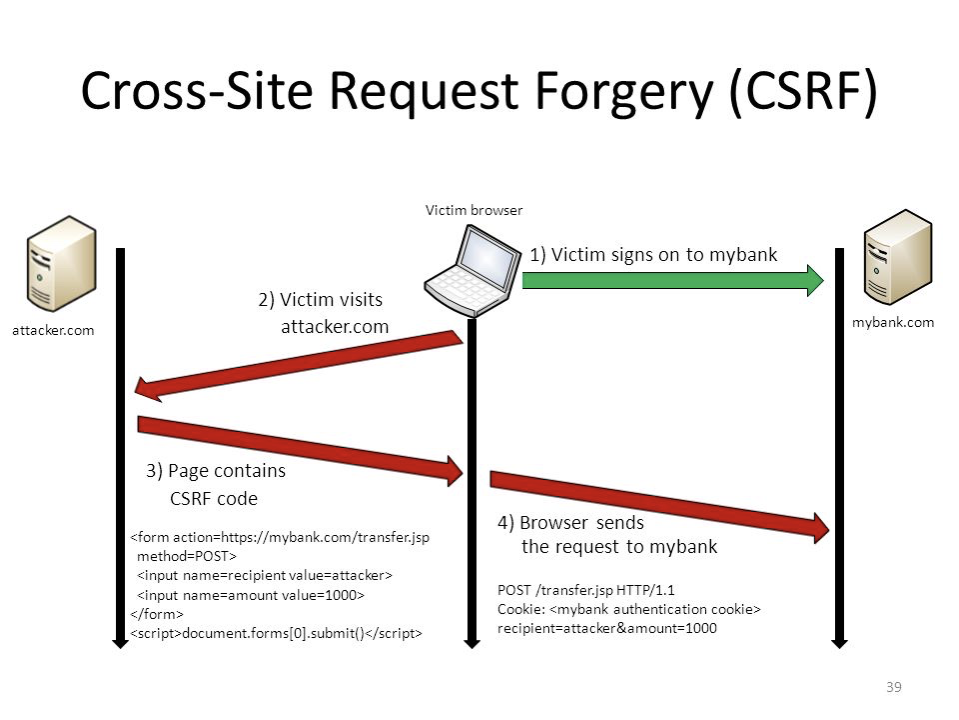
CSRF或XSRF(Cross-site Request Forgery),即跨站请求伪造。它也被称为:one click
attack/session riding,是一种对网站的恶意利用。它伪装成来自受信任用户发起请求,难以防范。
原理
1 2 3 4 5 1. 用户登录某网站A完成登录认证,网站返回敏感信息的Cookie,即使是会话级的Cookie2. 用户没有关闭浏览器,或认证的Cookie一段时间内不过期还持久化了,用户就访问攻击网站B3. 攻击网站B看似一切正常,但是某些页面里面有一些隐藏运行的代码,或者诱骗用户操作的按钮等4. 这些代码一旦运行就是悄悄地向网站A发起特殊请求,由于网站A的Cookie还有效,且访问的是网站A,则其Cookie就可以一并发给网站A5. 网站A看到这些Cookie就只能认为是登录用户发起的合理合法的请求,就会执行
CSRF解决
关闭CSRF中间件(不推荐)
1 2 3 4 5 6 7 8 9 MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware' , 'django.contrib.sessions.middleware.SessionMiddleware' , 'django.middleware.common.CommonMiddleware' , 'django.contrib.auth.middleware.AuthenticationMiddleware' , 'django.contrib.messages.middleware.MessageMiddleware' , 'django.middleware.clickjacking.XFrameOptionsMiddleware' , ]
2. csrftoken验证
- 在表单POST提交时,需要发给服务器一个csrf_token
- 模板中的表单Form中增加{% csrf_token %},它返回到了浏览器端就会为cookie增加 csrftoken 字段,还会在表单中增加一个名为csrfmiddlewaretoken隐藏控件
- POST提交表单数据时,需要将csrfmiddlewaretoken一并提交,Cookie中的csrf_token 也一 并会提交,最终在中间件中比较,相符通过,不相符就看到上面的403提示
- 假设正常网站为A,攻击网站为B,在访问网站B网页时,这个网页并不是来自网站A的网页, 而只是在这个网页中包含着提交到网站A的请求的代码,注意只有访问网站A返回的HTML页 面,才会有{% csrf_token %}产生set-cookie和input hidden。网站B的网页恶意代码执行, 由于发起对网站A的请求,会带上cookie,但是没有input hidden带的值,验证失败
2. 双cookie验证
- 访问本站先获得csrftoken的cookie
- 如果使用AJAX进行POST,需要在每一次请求Header中增加自定义字段X-CSRFTOKEN,其值 来自cookie中获取的csrftoken值
- 在服务器端比较cookie和X-CSRFTOKEN中的csrftoken,相符通过
- 假设正常网站为A,攻击网站为B,双Cookie验证中,用户访问攻击网站B时,网站B网页中代 码悄悄发起对A的请求,由于跨域不能获得正常网站A的Cookie值,它只能发起请求时,浏览器自动带上A的Cookie,但是A检查请求头中并没有X-CSRFTOKEN的值,或这个随机token值 对不上,验证失败 现在没有前端代码,为了测试方便,可以选择第一种方法先禁用中间件,测试完成后开启。
视图类 视图类(Class-based View),即视图功能由一个类和其方法实现
参考:https://docs.djangoproject.com/en/3.2/topics/class-based-views/
View类原理
django.views.View类本质就是一个对请求方法分发到与请求方法同名函数的调度器。
1 2 3 4 5 6 from django.urls import pathfrom .views import TestIndex urlpatterns = [ path('' , TestIndex.as_view()), ]
django.views.View类,定义了http的方法的小写名称列表,这些小写名称其实就是处理请求的方法名的 小写。
View类的类方法as_view()方法调用后返回一个内建的 view(request, *args, **kwargs) 新函数(为 了后面叙述方便,称它为fn),本质上其实还是url映射到了这个fn函数上。注意这个fn函数的签名,就 是视图函数的签名。
请求request到来后,直接发给fn函数,fn函数内部
构建TestIndex实例self。注意:阅读源码可以看到,每一个请求创建一个实例
dispatch派发请求,self.dispatch(request, *args, **kwargs) dispatch方法内部比对请求方法method,如果存在请求的get、post等方法,则调用,否则返回405 看到了getattr等反射函数,说明基于反射实现的。
本质上,as_view()方法还是把一个类伪装成了一个视图函数。
这个视图函数,内部使用了一个分发函数,使用请求方法名称把请求分发给存在的同名函数处理。
视图类实现 1 2 3 4 5 6 7 8 9 10 from django.http import HttpRequest, HttpResponse, JsonResponsefrom django.views import Viewclass TestIndex (View) : def get (self, request) : data = {'a' :100 , 'b' :'abc' } return JsonResponse(data) def post (self, request) : data = {'a' :200 , 'b' :'xyz' } return JsonResponse(data)
装饰器 由上面的原理分析,as_view()后,就可以看做是一个普通的视图函数。由此,得到方法装饰器的一种用法。
1 2 3 4 5 6 7 8 from django.urls import pathfrom .views import TestIndex from django.views.decorators.http import require_http_methods, require_GETurlpatterns = [ path('' , require_http_methods(['POST' ])(TestIndex.as_view())), ]
装饰器本质就是函数调用, require_http_methods([‘POST’])(TestIndex.as_view()) 返回一个新 的视图函数。
虽然,TestIndex有get、post方法,但是之前却要现经过require_http_methods函数检查。
中间件 洋葱模型 中间件和视图,如同洋葱一层层包裹着最中心的视图,想要见到视图函数或返回给浏览器端很不容易, 需要在来路和去路都要经过这些中间件。
get_response 非常重要,表示去调用下一层的对象。对象可能是下一级中间件,也可能是洋葱心儿 —— 视图。
在阅读wsgi.py源码中,进入 django.core.handlers.wsgi.WSGIHandler 类,可以看到 init 中 加载了中间件,在 call 中调用了get_response。
中间件定义 Django1.10版本开始,中间件帮助文档已经不能很好的体现其技术原理了。在官网切换到1.8版本帮 助,看到下面内容:https://docs.djangoproject.com/en/1.8/topics/http/middleware/
再看看目前的版本的文档:https://docs.djangoproject.com/en/3.2/topics/http/middleware/
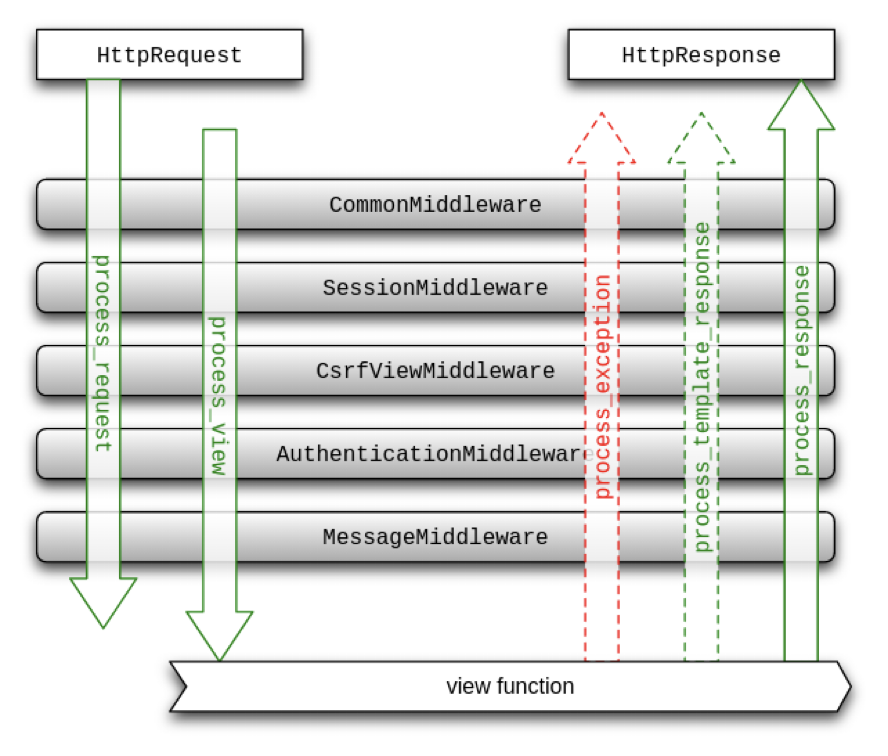
从文档中可以看出保留 process_view、process_exception、process_template_response 这些钩子函数。
process_view参考:https://docs.djangoproject.com/en/3.2/topics/http/middleware/#process-view
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 applicaiton __init__ __call__ environ -> request对象 response = get_response(request) start_response() return [response.body] class SimpleMiddleware : def __init__ (self, get_response) : self.get_response = get_response def __call__ (self, request) : response = self.get_response(request) return response
新建包utils,在里面增加一个middlewares.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from django.http import HttpResponseclass MagMiddleware1 : def __init__ (self, get_response) : """执行一次""" print(self.__class__.__name__, "init~~~~" ) self.get_response = get_response def __call__ (self, request) : print(self.__class__.__name__, "__call__~~~~" ) response = self.get_response(request) print(self.__class__.__name__, "__call__#####" ) return response def process_view (self, request, view_func, view_args, view_kwargs) : """调用视图前被调用,返回值是None或HttpResponse对象""" print(self.__class__.__name__, "process_view~~~~" , view_func.__name__, view_args, view_kwargs) class MagMiddleware2 : def __init__ (self, get_response) : """执行一次""" print(self.__class__.__name__, "init~~~~" ) self.get_response = get_response def __call__ (self, request) : print(self.__class__.__name__, "__call__~~~~" ) response = self.get_response(request) print(self.__class__.__name__, "__call__#####" ) return response def process_view (self, request, view_func, view_args, view_kwargs) : """调用视图前被调用,返回值是None或HttpResponse对象""" print(self.__class__.__name__, "process_view~~~~" , view_func.__name__, view_args, view_kwargs)
定义2个中间件,注册
1 2 3 4 5 6 7 8 9 10 11 MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware' , 'django.contrib.sessions.middleware.SessionMiddleware' , 'django.middleware.common.CommonMiddleware' , 'django.middleware.csrf.CsrfViewMiddleware' , 'django.contrib.auth.middleware.AuthenticationMiddleware' , 'django.contrib.messages.middleware.MessageMiddleware' , 'django.middleware.clickjacking.XFrameOptionsMiddleware' , 'utils.middlewares.MagMiddleware1' , 'utils.middlewares.MagMiddleware2' ]
将测试代码中 测试点 打开,观察效果,理解中间件原理。
原理
结论
Django中间件使用的洋葱式,但有特殊的地方
settings.py中配置着中间件的顺序 中间件初始化一次,但是初始化顺序和配置序相反,如同包粽子,先从芯开始包
新版中间件先在 call 中 get_response(request) 之前代码(相当于老版本中的 process_request)
按照配置顺序先后执行所有中间件的get_response(request)之前代码
全部执行完解析路径映射得到 view_func
process_view 函数按照配置顺序,依次向后执行
return None 继续向后执行
return HttpResponse() 就不在执行其它函数的 preview 函数了,此函数返回值作为浏览器端 的响应
执行view函数,前提是前面的所有中间件 process_view 都返回 None
逆序执行所有中间件的 get_response(request) 之后代码
特别注意,如果 get_response(request) 之前代码中 return HttpResponse(),将从当前中间件立即 返回给浏览器端,从洋葱中依次反弹
应用 应用场景:如果绝大多数请求或响应都需要拦截,个别例外,采用中间件较为合适。
中间件有很多用途,适合拦截所有请求和响应。例如浏览器端的IP是否禁用、UserAgent分析、异常响 应的统一处理
内建中间件
SessionMiddleware 从请求报文中提取 sessionid,提供 request.session 属性
AuthenticationMiddleware 依赖 SessionMiddleware,提供 request.user属性。根据 session 认证,如果成功,request.user 就是可用的用户对象,is_authenticated 为 True;如果失败,返回一 个匿名用户对象,is_authenticated 为 False。
Session和Cookie 浏览器端和服务器端身份认证的一种方式。简单讲,就是为了让服务端确定你是谁。
Cookie技术
键值对信息
是一种客户端、服务器端传递数据的技术
一般来说cookie信息是在服务器端生成,返回给浏览器端的
浏览器端可以保持这些值,浏览器对同一域发起每一请求时,都会把Cookie信息发给服务器端
服务端收到浏览器端发过来的Cookie,处理这些信息,可以用来判断这次请求是否和之前的请求有 关联
曾经Cookie唯一在浏览器端存储数据的手段,目前浏览器端存储数据的方案很多,Cookie正在被淘汰。
当服务器收到HTTP请求时,服务器可以在响应头里面添加一个Set-Cookie键值对。浏览器收到响应后通 常会保存这些Cookie,之后对该服务器每一次请求中都通过Cookie请求头部将Cookie信息发送给服务 器。
另外,Cookie的过期时间、域、路径、有效期、适用站点都可以根据需要来指定。 可以使用 Set-Cookie:NAME=VALUE;Expires=DATE;Path=PATH;Domain=DOMAIN_NAME;SECURE
例如:
1 2 3 4 Set-Cookie:aliyungf_tc=AQAAAJDwJ3Bu8gkAHbrHb4zlNZGw4Y; Path=/; HttpOnly set-cookie:test_cookie=CheckForPermission; expires=Tue, 19 -Mar-2018 15 :53 :02 GMT; path=/; domain=.doubleclick.net Set-Cookie: BD_HOME=1 ; path=/
key
value说明
Cookie过期
Cookie可以设定过期终止时间,过期后将被浏览器清除。
Cookie域
域确定有哪些域可以存取这个Cookie。 www.magedu.com 。
Path
确定哪些目录及子目录访问可以使用该Cookie
Secure 表示Cookie随着HTTPS加密过得请求发送给服务端
HttpOnly
将Cookie设置此标记,就不能被JavaScript访问,只能发给服务器端
1 2 3 4 5 6 7 8 9 10 11 12 13 Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07 :28 :00 GMT; Secure; HttpOnly 告诉浏览器端设置这个Cookie的键值对,有过期时间,使用HTTPS加密传输到服务器端,且不能被浏览器中JS脚本访问该Cookie Cookie的作用域:Domain和Path定义Cookie的作用域 Domain domain=www.magedu.com 表示只有该域的URL才能使用 domain=magedu.com 表示可以包含子域,例如www.magedu.com、python.magedu.com等 Path path=/ 所有/的子路径可以使用 domain=www.magedu.com; path=/webapp 表示只有www.magedu.com/webapp下的URL匹配,例 如http://www.magedu.com/webapp/a.html就可以
缺点
Cookie一般明文传输(Secure是加密传输),安全性极差,不要传输敏感数据
有4kB大小限制
每次请求中都会发送Cookie,增加了流量
其它持久化技术 LocalStorage
浏览器端持久化方案之一,HTML5标准增加的技术
依然采用键值对存储数据
数据会存储在不同的域名下面
不同浏览器对单个域名下存储数据的长度支持不同,有的最多支持2MB。
https://developer.mozilla.org/zh-CN/docs/Web/API/Window/localStorage
SessionStorage和LocalStorage差不多,它是会话级的,浏览器关闭,会话结束,数据清除。
IndexedDB
一个域一个datatable
key-valuede检索方式
建立在关系型的数据模型之上,具有索引表、游标、事务等概念
Session技术 WEB 服务器端,尤其是动态网页服务端Server,有时需要知道浏览器方是谁?但是HTTP是无状态的,怎么办?
服务端会为每一次浏览器端第一次访问生成一个SessionID,用来唯一标识该浏览器,通过响应报文的Set-Cookie发送到浏览器端。
1 Set-Cookie:SESSIONID=741248 A52EEB83DF182009912A4ABD86.Tomcat1;Path=/; HttpOnly
浏览器端收到之后并不永久保持这个Cookie,可以是会话级的。浏览器访问服务端时,会使用与请求域 相关的Cookies,也会带上这个SessionID的Cookie值。
动态网页技术,也需要知道用户身份,但是HTTP是无状态协议,无法知道。必须提出一种技术,让客户 端提交的信息可以表明身份。只能是服务端发出一个凭证,即SessionID,让浏览器端每次请求时发出 Cookies的同时带上这个SessionID,且过期作废,浏览器还不能更改。这个技术为了给浏览器发凭证就 使用了现有的Cookie技术。
服务端会维持这个SessionID一段时间,如果超时,会清理这些超时没有人访问的SessionID。如果浏览 器端发来的SessionID无法在服务端找到,就会自动再次分配新的SessionID,并通过Set-Cookie发送到 浏览器端以覆盖原有的存在浏览器中的会话级的SessionID。
也就是说服务器端会为浏览器端在内存开辟空间保存SessionID,同时和这个SessionID关联存储更多键 值对。这种为客户端在服务端维护相关状态数据的技术,就是Session技术。
推荐图书《HTTP权威指南》
Session开启后,会为浏览器端设置一个Cookie值,即SessionID。 这个SessionID的Cookie如果是会话级的,浏览器不做持久化存储只放在内存中,并且浏览器关闭自动 清除。 浏览器端发起HTTP请求后,这个SessionID会通过Cookie发到服务器端,服务器端就可以通过这个ID查 到对应的一个字典结构。如果查无此ID,就为此浏览器重新生成一个SessionID,为它建立一个 SessionID和空字典的映射关系。
可以在这个SessionID关联的字典中,存入键值对来保持与当前会话相关的更多信息
Session会定期过期清除
Session占用服务器端内存
Session如果没有持久化,如果服务程序崩溃,那么所有Session信息丢失
Session可以持久化到数据库中,如果服务程序崩溃,那么可以从数据库中恢复
开启session支持 Django可以使用Session
在 settings 中,MIDDLEWARE 设置中,启用 ‘django.contrib.sessions.middleware.SessionMiddleware’
INSTALLED_APPS 设置中,启用 ‘django.contrib.sessions’。它是基于数据库存储的 Session
Session 不使用,可以关闭上述配置,以减少开销
在数据库的表中的 django_session 表,记录 session 信息。但可以使用文件系统或其他 cache 来存储
session清除 登录成功,为当前session在django_session表中增加一条记录,如果没有显式调用logout函数或
request.session.flush(),那么该记录不会消失。Django也没有自动清除失效记录的功能。 request.session.flush()会清除当前session,同时删除表记录。 但Django提供了一个命令clearsessions,建议放在cron中定期执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 $ django-admin.py clearsessions $ manage.py clearsessions from django.http import HttpRequest, HttpResponsedef test_index (request:HttpRequest) : '''cookie和session测试''' print('~' * 30 ) print(request.session.get('abc' )) res = HttpResponse('test' ) res.cookies['tttt' ] = 'vvvvvv' print(request.session.keys()) request.session['abc' ] = str(random.randint(100 , 200 )) print('~' * 30 ) return res from django.contrib.sessions.models import Sessions = Session.objects.get(pk='m600uyia87y0imcn6ghwfv79hgotyf4r' ) print(s.expire_date) print(s.session_data) print(s.get_decoded())
DRF及序列化器原理 DRF(Django Rest Framework)是可以快速基于Restful开发的Django应用的插件,功能非常多,被广 泛应用。
安装
1 $ pip install djangorestframework
Django 需要 2.2+
注册
settings.py中增加
1 2 3 4 INSTALLED_APPS = [ ... 'rest_framework' , ]
序列化器 采用前后端分离后
序列化:后端发给前端的数据就是Json,核心就是把数据结构序列化成Json发给浏览器端
字典 => Json字符串
更进一步,实例 => 字典,字典交给Response类序列化成Json
反序列化:前端发给后端的数据依然是request请求,但是提交的数据是Json,需要反序列化
Json字符串 => 字典 一般建议使用字典包封装数据。
序列化器类 参考:https://www.django-rest-framework.org/api-guide/serializers/
rest_framework.serializers.BaseSerializer是序列化器类的基类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class BaseSerializer (Field) : def __init__ (self, instance=None, data=empty, **kwargs) : self.instance = instance if data is not empty: self.initial_data = data self.partial = kwargs.pop('partial' , False ) self._context = kwargs.pop('context' , {}) kwargs.pop('many' , None ) super().__init__(**kwargs) def is_valid (self, raise_exception=False) : """反序列化时校验数据,也就是对浏览器端提交的数据进行验证""" @property def data (self) : if hasattr(self, 'initial_data' ) and not hasattr(self, '_validated_data' ): msg = ( 'When a serializer is passed a `data` keyword argument you ' 'must call `.is_valid()` before attempting to access the ' 'serialized `.data` representation.\n' 'You should either call `.is_valid()` first, ' 'or access `.initial_data` instead.' ) raise AssertionError(msg) if not hasattr(self, '_data' ): if self.instance is not None and not getattr(self, '_errors' , '_errors' , None ): self._data = self.to_representation(self.instance) elif hasattr(self, '_validated_data' ) and not getattr(self, self._data = self.to_representation(self.validated_data) else : self._data = self.get_initial() return self._data @property def validated_data (self) : """校验后获取反序列化的数据""" class Serializer (BaseSerializer, metaclass=SerializerMetaclass) : @property def data (self) : ret = super().data return ReturnDict(ret, serializer=self)
序列化器原理 序列化器 在应用目录下构建serializers.py,根据Model类Employee编写EmpSerializer。 需要什么字段就在EmpSerializer中定义什么属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from rest_framework import serializersfrom .models import Employeeclass EmpSerializer (serializers.Serializer) : emp_no = serializers.IntegerField() birth_date = serializers.DateField() first_name = serializers.CharField(max_length=14 ) last_name = serializers.CharField(max_length=16 ) gender = serializers.ChoiceField(choices=Employee.Gender.choices) hire_date = serializers.DateField() print('~' * 30 ) print(EmpSerializer()) print('~' * 30 )
序列化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import osimport djangoos.environ.setdefault('DJANGO_SETTINGS_MODULE' , 'salary.settings' ) django.setup(set_prefix=False ) from employee.models import Employeefrom employee.serializers import EmpSerializeremgr = Employee.objects emp = emgr.get(pk=10010 ) print(emp) serializer = EmpSerializer(instance=emp) data = serializer.data print(type(data), data) emps = emgr.filter(pk__gt=10017 ) print(*emps) serializer = EmpSerializer(emps, many=True ) data = serializer.data print(type(data), data)
反序列化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import osimport djangoos.environ.setdefault('DJANGO_SETTINGS_MODULE' , 'salary.settings' ) django.setup(set_prefix=False ) from employee.models import Employeefrom employee.serializers import EmpSerializeremgr = Employee.objects data = { 'emp_no' : 10010 , 'birth_date' : '1963-06-01' , 'first_name' : 'Duangkaew' , 'last_name' : 'Piveteau' , 'gender' : '2' , 'hire_date' : '1989-08-24' } serializer = EmpSerializer(data=data) validated = serializer.is_valid(raise_exception=True ) print(validated) print(serializer.data)
校验 对浏览器端提交的数据一定要校验,所以,校验是入库前必须要做的。
字段选项参数校验
字符串长度
长度测试min_length和max_length
1 2 3 4 t1 = serializers.CharField(label="长度限制和必须" , min_length=4 , max_length=8 ) 测试 "t1" : "ab" 错误 {'t1' : [ErrorDetail(string='Ensure this field has at least 4 characters.' , code='min_length' )]} 注意,异常返回的[]列表,说明一个字段可以有多个校验器,这和前端开发校验一样
字段值是否必须
字段默认require=True,也就是说必须提供
1 2 3 t1=serializers.CharField(label="长度限制和必须" ,min_length=4 , max_length=8 ) 测试 Post的数据不提供t1 错误 {'t1' : [ErrorDetail(string='This field is required.' ,code='required' )]}
只读
read_only不校验该字段,只会出现在序列化中,仅仅只能给人看
read_only和require不可以同时为True
read_only=True表示序列化时可以序列化t2这个属性的数据,反序列化不使用它,提供了值 也不校验也不输出,serializer.data输出结果中没有t2
1 t2=serializers.CharField(read_only=True )
只写
write_only=True,表示反序列化用,要校验。不会被序列化,不返回给浏览器
1 t3=serializers.CharField(write_only=True )
对序列化器 略作修改做测试,这个测试主要测试的是反序列化的校验
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from rest_framework import serializersfrom .models import Employeeclass EmpSerializer (serializers.Serializer) : emp_no = serializers.IntegerField() birth_date = serializers.DateField() first_name = serializers.CharField(max_length=14 ) last_name = serializers.CharField(max_length=16 ) gender = serializers.ChoiceField(choices=Employee.Gender.choices) hire_date = serializers.DateField() t1 = serializers.CharField(label="长度限制和必须" , min_length=4 , max_length=8 ) t2 = serializers.CharField(read_only=True ) t3 = serializers.CharField(write_only=True ) import osimport djangoos.environ.setdefault('DJANGO_SETTINGS_MODULE' , 'salary.settings' ) django.setup(set_prefix=False ) from employee.models import Employeefrom employee.serializers import EmpSerializeremgr = Employee.objects emp = emgr.get(pk=10010 ) print(emp.__dict__) emp.t1 = 't1' emp.t2 = 't2' emp.t3 = 't3' serializer = EmpSerializer(instance=emp) data = serializer.data
序列化结果如下:
序列化时,不校验t1
t2是read_only,所以有它
t3是write_only,不参与序列化,所以没有它
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 {'emp_no' :10010 ,'birth_date' :'1963-06-01' ,'first_name' :'Duangkaew' , 'last_name' : 'Piveteau' , 'gender' : 2 , 'hire_date' : '1989-08-24' , 't1' : 't1' , 't2' : 't2' } import osimport djangoos.environ.setdefault('DJANGO_SETTINGS_MODULE' , 'salary.settings' ) django.setup(set_prefix=False ) from employee.models import Employeefrom employee.serializers import EmpSerializeremgr = Employee.objects data = { 'emp_no' : 10010 , 'birth_date' : '1963-06-01' , 'first_name' : 'Duangkaew' , 'last_name' : 'Piveteau' , 'gender' : "2" , 'hire_date' : '1989-08-24' , 't1' :'abcd' , 't2' :'t2++' , 't3' :'t3==' } serializer = EmpSerializer(data=data) validated = serializer.is_valid(raise_exception=True ) print(validated) print(serializer.data)
反序列化结果如下:
校验t1
t2是read_only,所以没有它
t3是write_only,反序列化必须有它,还要校验它
1 {'emp_no' : 10010 , 'birth_date' : datetime.date(1963 , 6 , 1 ), 'first_name' : 'Duangkaew' , 'last_name' : 'Piveteau' , 'gender' : 2 , 'hire_date' : datetime.date(1989 , 8 , 24 ), 't1' : 'abcd' , 't3' : 't3==' }
字段级校验器 参考:https://www.django-rest-framework.org/api-guide/serializers/#field-level-validation
这是针对某一个字段的校验,在序列化器类中增加validate_<字段名>方法,校验失败抛异常 serializers.ValidationError ,成功返回正确的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from rest_framework import serializersfrom .models import Employeeclass EmpSerializer (serializers.Serializer) : emp_no = serializers.IntegerField() birth_date = serializers.DateField() first_name = serializers.CharField() gender = serializers.ChoiceField(choices=Employee.Gender.choices) hire_date = serializers.DateField() def validate_first_name (self, value) : print(value, '+++++' ) if 4 <= len(value) <= 14 : return value raise serializers.ValidationError('The length must be between 4 and 14' )
还有一种写法,使用字段选项参数 validators=[validator, …]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from rest_framework import serializersfrom .models import Employeedef validate_fn (value) : print(value, '+++++' ) if 4 <= len(value) <= 14 : return value raise serializers.ValidationError('The length must be between 4 and 14' ) class EmpSerializer (serializers.Serializer) : emp_no = serializers.IntegerField() birth_date = serializers.DateField() first_name = serializers.CharField(validators=[validate_fn]) last_name = serializers.CharField(max_length=16 ) gender = serializers.ChoiceField(choices=Employee.Gender.choices) hire_date = serializers.DateField()
除非有复用的必要,不要把校验器定义在外部。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import osimport djangoos.environ.setdefault('DJANGO_SETTINGS_MODULE' , 'salary.settings' ) django.setup(set_prefix=False ) from employee.models import Employeefrom employee.serializers import EmpSerializeremgr = Employee.objects data = { 'emp_no' : 10010 , 'birth_date' : '1963-06-01' , 'first_name' : 'Duangkaew' , 'last_name' : 'Piveteau' , 'gender' : "2" , 'hire_date' : '1989-08-24' , } serializer = EmpSerializer(data=data) validated = serializer.is_valid(raise_exception=True ) print(validated) print(serializer.data)
对象级校验器 参考:https://www.django-rest-framework.org/api-guide/serializers/#object-level-validation
对象级校验器就是对实例所有字段数据的校验
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from rest_framework import serializersfrom .models import Employeeclass EmpSerializer (serializers.Serializer) : emp_no = serializers.IntegerField() birth_date = serializers.DateField() first_name = serializers.CharField() last_name = serializers.CharField(max_length=16 ) gender = serializers.ChoiceField(choices=Employee.Gender.choices) hire_date = serializers.DateField() def validate_first_name (self, value) : if 4 <= len(value) <= 14 : return value raise serializers.ValidationError('The length must be between 4 and 14' ) def validate (self, data) : print(data, '====' ) last_name = data.get('last_name' , '' ) if len(last_name) < 2 : raise serializers.ValidationError('The length must be greater than 1' ) return data
入库 参考:https://www.django-rest-framework.org/api-guide/serializers/#saving-instances
校验后的数据是安全的,可以写入数据库。
原理
BaseSerializer中定义了save方法
save()之前一定要.is_valid()
BaseSerializer(instance=None, data=empty),无实例就是新增,调用create;有实例就是更新, 调用update。最终返回实例
在BaseSerializer中,create、update是未实现的抽象方法,Serializer也没有实现这2个方法。言 下之意,就是需要用户自己实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from rest_framework import serializersfrom .models import Employeeclass EmpSerializer (serializers.Serializer) : emp_no = serializers.IntegerField() birth_date = serializers.DateField() first_name = serializers.CharField(max_length=14 ) last_name = serializers.CharField(max_length=16 ) gender = serializers.ChoiceField(choices=Employee.Gender.choices) hire_date = serializers.DateField() def create (self, validated_data) : return Employee.objects.create(**validated_data) def update (self, instance:Employee, validated_data) : instance.first_name = validated_data.get('first_name' , instance.first_name) instance.last_name = validated_data.get('last_name' , instance.last_name) instance.gender = validated_data.get('gender' , instance.gender) instance.save() return instance
增
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import osimport djangoos.environ.setdefault('DJANGO_SETTINGS_MODULE' , 'salary.settings' ) django.setup(set_prefix=False ) from employee.models import Employeefrom employee.serializers import EmpSerializeremgr = Employee.objects data = { 'emp_no' : 10021 , 'birth_date' : '1963-06-01' , 'first_name' : 'san' , 'last_name' : 'zhang' , 'gender' : "1" , 'hire_date' : '1989-08-24' , } serializer = EmpSerializer(data=data) validated = serializer.is_valid(raise_exception=True ) serializer.save() print(serializer.data)
改
先查再改:先查返回结果填充实例,然后根据这个实例修改数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import osimport djangoos.environ.setdefault('DJANGO_SETTINGS_MODULE' , 'salary.settings' ) django.setup(set_prefix=False ) from employee.models import Employeefrom employee.serializers import EmpSerializeremgr = Employee.objects emp = emgr.get(pk=10021 ) print(emp) data = { 'emp_no' : 10021 , 'birth_date' : '1963-06-01' , 'first_name' : 'si' , 'last_name' : 'li' , 'gender' : 1 , 'hire_date' : '1989-08-24' , } serializer = EmpSerializer(emp, data=data) validated = serializer.is_valid(raise_exception=True ) serializer.save() print(serializer.data)
总结
序列化
查库:查询数据库得到单个实例或多个实例
构造序列化器实例:构造序列化器实例
输出:使用data属性获取字典
反序列化
反序列化:将Json数据反序列化为字典
构造序列化器实例:使用字典构造序列化器实例
校验:调用is_valid方法校验各个字段的值
入库:调用save方法
从前面的知识点可以明白DRF的基本原理,也感觉到了Serializer类比较简陋,很多东西都需要自己写代码。 可以观察到,序列化器字段定义和Model类中的严重重复,能否利用Model类来简化?
所有的增、改都差不多,能否把create、update也实现了?
ModelSerializer 参考:https://www.django-rest-framework.org/api-guide/serializers/#modelserializer
ModelSerializer是Serializer的子类除了具有Serializer的功能外:
根据Model类,自动生成字段
为序列化器自动生成校验器
为序列化器提供了简单的create()和update()方法实现,所以可以直接save()
序列化器 需要解决2个问题:
依照那个Model类 需要哪些字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 from rest_framework import serializersfrom .models import Employeeclass EmpSerializer (serializers.ModelSerializer) : class Meta : model = Employee fields = '__all__' print('~' * 30 ) print(EmpSerializer()) print('~' * 30 ) EmpSerializer(): emp_no = IntegerField(label='工号' , max_value=2147483647 , min_value=-2147483648 , validators= [<UniqueValidator(queryset=Employee.objects.all())>]) birth_date = DateField(label='生日' ) first_name = CharField(label='名' , max_length=14 ) last_name = CharField(label='姓' , max_length=16 ) gender = ChoiceField(choices=[(1 , '男' ), (2 , '女' )], label='性别' , validators=[<django.core.validators.MinValueValidator object>, <django.core.validators.MaxValueValidator object>]) hire_date = DateField() class EmpSerializer (serializers.ModelSerializer) : class Meta : model = Employee fields = ['emp_no' , 'first_name' , 'last_name' ] class EmpSerializer (serializers.ModelSerializer) : class Meta : model = Employee exclude = ['gender' ] class EmpSerializer (serializers.ModelSerializer) : class Meta : model = Employee fields = '__all__' read_only_fields = ['hire_date' ] class EmpSerializer (serializers.ModelSerializer) : class Meta : model = Employee fields = '__all__' read_only_fields = ['hire_date' ] extra_kwargs = {'gender' : {'write_only' : True }}
序列化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class EmpSerializer (serializers.ModelSerializer) : class Meta : model = Employee fields = '__all__' import osimport djangoos.environ.setdefault('DJANGO_SETTINGS_MODULE' , 'salary.settings' ) django.setup(set_prefix=False ) from employee.models import Employeefrom employee.serializers import EmpSerializeremgr = Employee.objects emp = emgr.get(pk=10010 ) serializer = EmpSerializer(emp) print(serializer.data) {'emp_no' : 10010 , 'birth_date' : '1963-06-01' , 'first_name' : 'Duangkaew' , 'last_name' : 'Piveteau' , 'gender' : 2 , 'hire_date' : '1989-08-24' } emgr = Employee.objects emps = emgr.filter(pk__gt=10018 ) serializer = EmpSerializer(emps, many=True ) [OrderedDict([('emp_no' , 10019 ), ('birth_date' , '1953-01-23' ), ('first_name' ,'Lillian' ), ('last_name' , 'Haddadi' ), ('gender' , 1 ), ('hire_date' , '1999-04-30' )]), OrderedDict([('emp_no' , 10020 ), ('birth_date' ,'1952-12-24' ),('first_name' , 'Mayuko' ), ('last_name' , 'Warwick' ), ('gender' , 1 ), ('hire_date' , '1991-01-26' )]), OrderedDict([('emp_no' , 10021 ), ('birth_date' ,'1963-06-01' ), ('first_name' , 'si' ), ('last_name' , 'li' ), ('gender' , 1 ), ('hire_date' , '1989-08-24' )])]
反序列化 ModelSerializer提供了create、update方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import osimport djangoos.environ.setdefault('DJANGO_SETTINGS_MODULE' , 'salary.settings' ) django.setup(set_prefix=False ) from employee.models import Employeefrom employee.serializers import EmpSerializerdata = { 'emp_no' : 10022 , 'birth_date' : '1963-06-01' , 'first_name' : 'wu' , 'last_name' : 'wang' , 'gender' : 1 , 'hire_date' : '1989-08-24' , } serializer = EmpSerializer(data=data) serializer.is_valid(True ) x = serializer.save() print(type(x), x) emgr = Employee.objects emp = emgr.get(pk=10022 ) data = { 'emp_no' : 10022 , 'birth_date' : '1963-06-01' , 'first_name' : '三' , 'last_name' : '张' , 'gender' : 1 , 'hire_date' : '1989-08-24' ,} serializer = EmpSerializer(emp, data=data) serializer.is_valid(True ) x = serializer.save() print(type(x), x)
外键关系 员工和工资,是一对多关系
Model类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from django.db import models class Employee (models.Model) :class Gender (models.IntegerChoices) : MAN = 1 , '男' FEMALE = 2 , '女' class Meta : db_table = 'employees' verbose_name = '员工' emp_no = models.IntegerField(primary_key=True , verbose_name='工号' ) birth_date = models.DateField(verbose_name='生日' ) first_name = models.CharField(max_length=14 , verbose_name='名' ) last_name = models.CharField(max_length=16 , verbose_name='姓' ) gender = models.SmallIntegerField(verbose_name='性别' , choices=Gender.choices) hire_date = models.DateField() class Salary (models.Model) : class Meta : db_table = "salaries" emp_no = models.ForeignKey(Employee, on_delete=models.CASCADE, db_column='emp_no' , related_name='salaries' ) from_date = models.DateField() salary = models.IntegerField(verbose_name='工资' ) to_date = models.DateField()
序列化器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from rest_framework import serializersfrom .models import Employee, Salaryclass EmpSerializer (serializers.ModelSerializer) : class Meta : model = Employee fields = '__all__' class SalarySerializer (serializers.ModelSerializer) : class Meta : model = Salary fields = '__all__' print('~' * 30 ) print(EmpSerializer()) print(SalarySerializer()) print('~' * 30 )
序列化器如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 EmpSerializer(): emp_no = IntegerField(label='工号' , max_value=2147483647 , min_value=-2147483648 , validators= [<UniqueValidator(queryset=Employee.objects.all())>]) birth_date = DateField(label='生日' ) first_name = CharField(label='名' , max_length=14 ) last_name = CharField(label='姓' , max_length=16 ) gender = ChoiceField(choices=[(1 , '男' ), (2 , '女' )], label='性别' , validators=[<django.core.validators.MinValueValidator object>, <django.core.validators.MaxValueValidator object>]) hire_date = DateField() SalarySerializer(): id = IntegerField(label='ID' , read_only=True ) from_date = DateField() salary = IntegerField(label='工资' , max_value=2147483647 , min_value=-2147483648 ) to_date = DateField() emp_no = PrimaryKeyRelatedField(queryset=Employee.objects.all())
SalarySerializer有一个外键关联
序列化 各自独立查询 先查员工,再去查相关工资信息
1 2 3 4 5 6 7 8 9 10 11 12 13 import osimport djangoos.environ.setdefault('DJANGO_SETTINGS_MODULE' , 'salary.settings' ) django.setup(set_prefix=False ) from employee.models import Employeefrom employee.serializers import EmpSerializer, SalarySerializeremgr = Employee.objects emp = emgr.get(pk=10003 ) print(EmpSerializer(emp).data) print(SalarySerializer(emp.salaries.all(), many=True ).data)
关联主键 参考:https://www.django-rest-framework.org/api-guide/relations/#primarykeyrelatedfield
直接获取所有关联pk ,利用 serializers.PrimaryKeyRelatedField 来关联
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from rest_framework import serializersfrom .models import Employee, Salaryclass EmpSerializer (serializers.ModelSerializer) : class Meta : model = Employee fields = '__all__' salaries = serializers.PrimaryKeyRelatedField(many=True , read_only=True ) serializers.PrimaryKeyRelatedField(queryset=Salary.objects.all(), many=True ) class SalarySerializer (serializers.ModelSerializer) : class Meta : model = Salary fields = '__all__' from employee.models import Employeefrom employee.serializers import EmpSerializer, SalarySerializeremgr = Employee.objects emp = emgr.get(pk=10003 ) print(EmpSerializer(emp).data) {'emp_no' : 10003 , 'salaries' : [24 , 25 , 26 , 27 , 28 , 29 , 30 ], 'birth_date' : '1959-12-03' , 'first_name' : 'Parto' , 'last_name' : 'Bamford' , 'gender' : 1 , 'hire_date' : '1986-08-28' }
关联字符串表达 参考:https://www.django-rest-framework.org/api-guide/relations/#stringrelatedfield
直接获取所有关联对象的字符串表达,需要用到 str
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from rest_framework import serializersfrom .models import Employee, Salaryclass EmpSerializer (serializers.ModelSerializer) : class Meta : model = Employee fields = '__all__' salaries = serializers.StringRelatedField(many=True ) class SalarySerializer (serializers.ModelSerializer) : class Meta : model = Salary fields = '__all__' from employee.models import Employeefrom employee.serializers import EmpSerializer, SalarySerializeremgr = Employee.objects emp = emgr.get(pk=10003 ) print(EmpSerializer(emp).data) 1 {'emp_no' : 10003 , 'salaries' : ['<S 24, 10003, 40006>' , '<S 25, 10003, 43616>' , '<S 26, 10003, 43466>' , '<S 27, 10003, 43636>' , '<S 28, 10003, 43478>' , '<S 29, 10003, 43699>' , '<S 30, 10003, 43311>' ], 'birth_date' : '1959-12-03' , 'first_name' : 'Parto' , 'last_name' : 'Bamford' , 'gender' : 1 , 'hire_date' : '1986-08-28' }
关联对象 参考:https://www.django-rest-framework.org/api-guide/relations/#nested-relationships
如果需要更加完整的关联数据,可以使用关联对象的方式,要利用对方的序列化器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from rest_framework import serializersfrom .models import Employee, Salaryclass SalarySerializer (serializers.ModelSerializer) : class Meta : model = Salary fields = '__all__' class EmpSerializer (serializers.ModelSerializer) : class Meta : model = Employee fields = '__all__' salaries = SalarySerializer(many=True , read_only=True ) from employee.models import Employeefrom employee.serializers import EmpSerializer, SalarySerializeremgr = Employee.objects emp = emgr.get(pk=10003 ) import jsonprint(json.dumps(EmpSerializer(emp).data))
返回的数据序列化成Json格式如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 { "emp_no" :10003 , "salaries" :[ { "id" :24 , "from_date" :"1995-12-03" , "salary" :40006 , "to_date" :"1996-12-02" , "emp_no" :10003 }, { "id" :25 , "from_date" :"1996-12-02" , "salary" :43616 , "to_date" :"1997-12-02" , "emp_no" :10003 }, { "id" :26 , "from_date" :"1997-12-02" , "salary" :43466 , "to_date" :"1998-12-02" , "emp_no" :10003 }, { "id" :27 , "from_date" :"1998-12-02" , "salary" :43636 , "to_date" :"1999-12-02" , "emp_no" :10003 }, { "id" :28 , "from_date" :"1999-12-02" , "salary" :43478 , "to_date" :"2000-12-01" , "emp_no" :10003 }, { "id" :29 , "from_date" :"2000-12-01" , "salary" :43699 , "to_date" :"2001-12-01" , "emp_no" :10003 }, { "id" :30 , "from_date" :"2001-12-01" , "salary" :43311 , "to_date" :"9999-01-01" , "emp_no" :10003 } ], "birth_date" :"1959-12-03" , "first_name" :"Parto" , "last_name" :"Bamford" , "gender" :1 , "hire_date" :"1986-08-28" }
DRF视图 请求传参
利用HTTP请求报文传递参数有3种方式
查询字符串,GET方法,参数在URL中, http://127.0.0.1:8000/emp/?x=123&x=abc&y=789
表单,前端网页中填写表单,一般使用POST方法,参数在body中
1 2 3 4 5 6 POST /xxx/yyy?id=5&name=magedu HTTP/1.1 HOST: 127.0 .0 .1 :9999 content-length: 26 content-type: application/x-www-form-urlencoded age=5 &weight=80 &height=170
也可以POST、PUT提交Json格式数据
URL本身就是数据的表达, http://127.0.0.1:8080/python/2010/u101
APIView 在Django中,View是视图类基类,路由配置中需要把类通过as_view()伪装成视图函数,请求通过路由 进入到这个视图函数中,内部为每一个请求实例化一个视图类实例,并根据request.method找到对应的 handler。而这个基本流程已经被View类固定在其内部,我们只需要定义get、post等方法即可,简化了 编程。
使用DRF,基于Django,也要使用View类。请求参数是Json格式,先要序列化它,然后验证,验证合格 可以入库。响应的数据应该序列化成Json格式。你会发现这也是固定的套路,是否也能够简化呢?
参考 https://www.django-rest-framework.org/api-guide/views/
APIView
as_view()调用基类View的,但是使用了csrf_exempt(view)来排除CSRF保护
重新定义了Request类来替代Django的,虽是重写,但是依然有联系
重新定义了Response类来增强替代Django的
异常类都是基于APIException类的
对请求进行认证和授权 APIView没有提供增删改查的handler方法,也就是说和View一样,需要自己定义get、post、put、delete方法。
GET请求测试 GET请求:http://127.0.0.1:8000/emp/?x=123&x=abc&y=789
1 2 3 4 5 6 7 8 9 10 11 12 13 from rest_framework.views import APIView, Request, Responseclass TestIndex (APIView) : def get (self, request:Request) : print('~' * 30 ) print(request.method) print('~' * 30 ) return Response({}) GET <QueryDict: {'x' : ['123' , 'abc' ], 'y' : ['789' ]}> <QueryDict: {'x' : ['123' , 'abc' ], 'y' : ['789' ]}> text/plain
QueryDict本质就是字典,对于同一个参数有多值情况使用了列表。
POST请求测试 POST请求:http://127.0.0.1:8000/emp/?x=123&x=abc&y=789
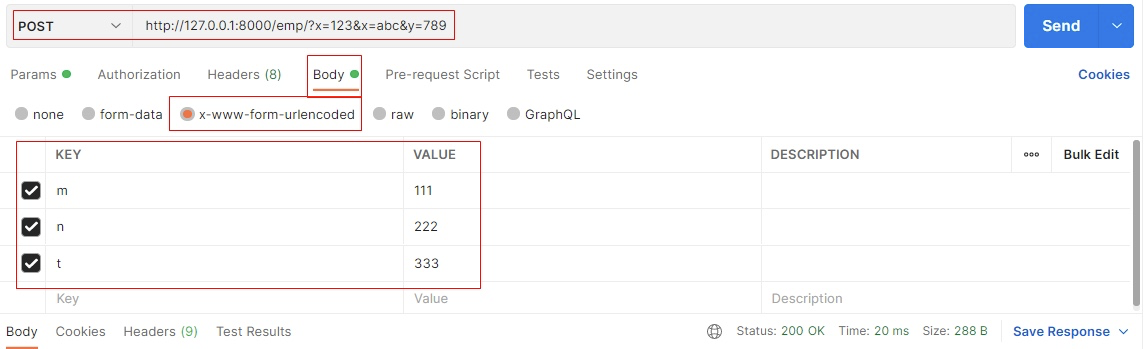
采用表单提交方式 1 2 3 4 5 6 7 8 9 10 11 12 13 from rest_framework.views import APIView, Request, Responseclass TestIndex (APIView) : def post (self, request:Request) : print('~' * 30 ) print(request.method) print(request.GET) print(request.query_params) print(request.content_type) print(request.POST) print(request.data) print('~' * 30 ) return Response({})
1 2 3 4 5 6 7 b'm=111&n=222&t=333' 这是request报文的body的原始数据POST <QueryDict: {'x' : ['123' , 'abc' ], 'y' : ['789' ]}> <QueryDict: {'x' : ['123' , 'abc' ], 'y' : ['789' ]}> application/x-www-form-urlencoded 表单提交的方法 <QueryDict: {'m' : ['111' ], 'n' : ['222' ], 't' : ['333' ]}> <QueryDict: {'m' : ['111' ], 'n' : ['222' ], 't' : ['333' ]}>
Json数据
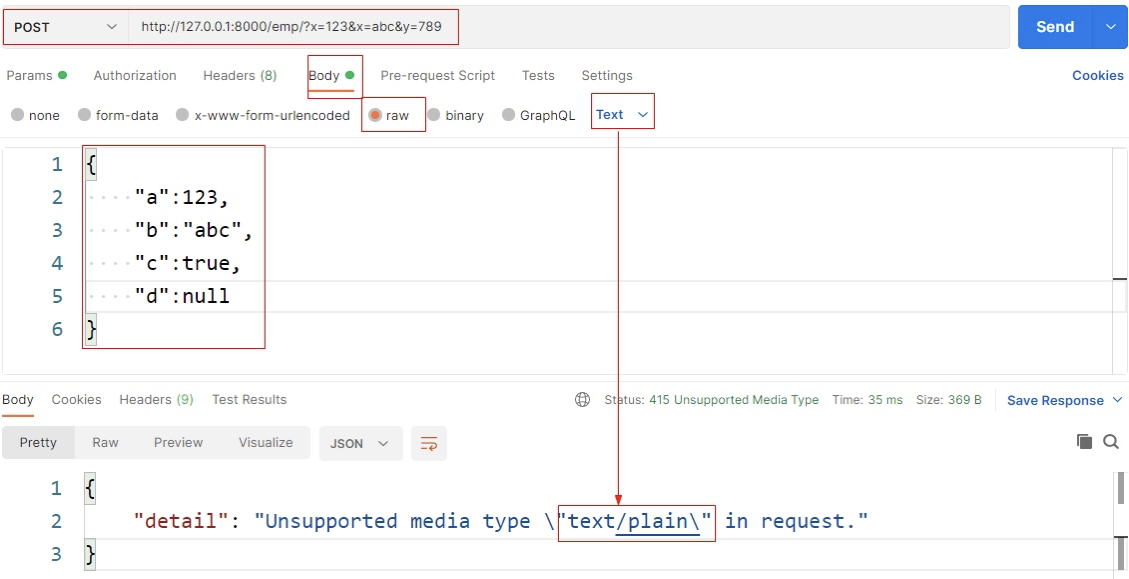
1 2 3 4 b'{\r\n "a":123,\r\n "b":"abc",\r\n "c":true,\r\n "d":null\r\n}' text/plain Unsupported Media Type: /emp/
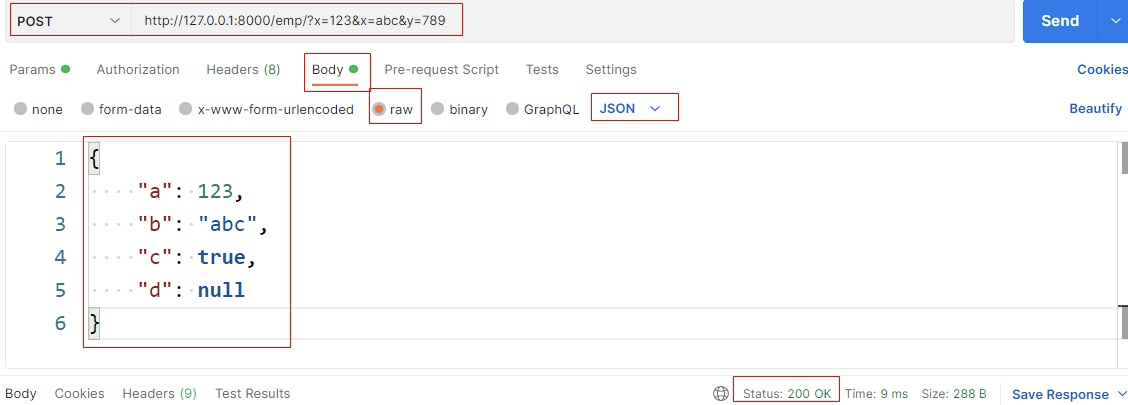
说明上例解析失败,原因就是类型选择了Text,改为Json
1 2 3 4 5 6 7 8 9 b'{\r\n "a": 123,\r\n "b": "abc",\r\n "c": true,\r\n "d": null\r\n}' POST <QueryDict: {'x' : ['123' , 'abc' ], 'y' : ['789' ]}> <QueryDict: {'x' : ['123' , 'abc' ], 'y' : ['789' ]}> application/json <QueryDict: {}> {'a' : 123 , 'b' : 'abc' , 'c' : True , 'd' : None }
请求总结
GET请求,查询字符串使用query_params提取
POST请求,访问data属性
支持了POST、PUT、PATCH方法(增、改)
统一将请求处理放到data属性中
如果是Json数据,帮我们序列化
响应 DRF对Django的响应类也做了增强,使用更加简单方便。
Response(data=None, status=None, template_name=None, headers=None,content_type=None)
兼具了模板渲染的能力
data将要序列化的数据,例如字典
staus状态码,默认200
headers响应报文头,字典
content_type响应内容类型,有时候需要手动设置
1 2 3 4 5 6 7 8 9 10 from rest_framework.views import APIView, Request, Responseclass TestIndex (APIView) : def get (self, request:Request) : print(request.query_params) def post (self, request:Request) : return Response({ 'host' :'python' , 'domain' :'magedu.com' }, status=201 , headers={'X-Server' :'Magedu' })
应用 需要构建2个类
列表页,返回列表和新增功能
详情页,基于主键的查看详情、修改、删除
路由 1 2 3 4 5 6 7 from django.urls import pathfrom .views import EmpsView, EmpViewurlpatterns = [ path('' , EmpsView.as_view()), path('<int:pk>/' , EmpView.as_view()), ]
列表页 1 2 3 4 5 6 7 8 from rest_framework.views import APIView, Request, Responseclass EmpsView (APIView) : """实现列表页get、新增post http://127.0.0.1:8000/emp/ """ def get (self, request) : pass def post (self, request) : pass
详情页 1 2 3 4 5 6 7 8 9 10 class EmpView (APIView) : """实现详情页get、修改put、删除delete http://127.0.0.1:8000/emp/10021 """ def get (self, request, pk:int) : pass def put (self, request, pk:int) : pass def delete (self, request, pk:int) : pass
异常处理(☆☆☆☆☆) 参考:https://www.django-rest-framework.org/api-guide/exceptions/
测试http://127.0.0.1:8000/emp/100,返回500服务器内部错误。
按平常做法,就应该出什么问题,返回什么出错信息。但这样做会有安全风险,且在浏览器端的普通用 户根本不管什么错误,就认为网站出问题了。所以,返回更加友好的出错页面是有必要的,例如更换 404页面。
我们的项目采用前后端分离,返回出错页面不合适,需要返回Json格式的出错信息,有必要拦截所有的 异常做处理。
异常全局配置 自定义全局异常处理器,参考 rest_framework.views.exception_handler 实现
1 2 3 REST_FRAMEWORK = { 'EXCEPTION_HANDLER' : 'utils.exceptions.global_exception_handler' }
全局异常处理 exception_handler会转化Django的Http404、PermissionDenied为DRF的基于APIException的类。 项目根目录下新建包utils,其中新建模块exceptions.py,内容如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 from django.http import Http404from django.core.exceptions import PermissionDeniedfrom rest_framework.views import set_rollbackfrom rest_framework import exceptionsfrom rest_framework.views import Response, exception_handlerclass MagBaseException (exceptions.APIException) : """基类定义基本的异常""" code = 10000 message = '非法请求' @classmethod def get_message (cls) : return {'code' : cls.code, 'message' : cls.message} exc_map = { } def global_exception_handler (exc, context) : """ 全局异常处理 照抄rest_framework.views.exception_handler,略作修改 不管什么异常这里统一处理。根据不同类型显示不同的 为了前端解析方便,这里响应的状态码采用默认的200 异常对应处理后返回对应的错误码和错误描述 异常找不到对应就返回缺省 """ if isinstance(exc, Http404): exc = exceptions.NotFound() elif isinstance(exc, PermissionDenied): exc = exceptions.PermissionDenied() print('异常' , '=' * 30 ) print(type(exc), exc.__dict__) print('=' * 30 ) if isinstance(exc, exceptions.APIException): headers = {} if getattr(exc, 'auth_header' , None ): headers['WWW-Authenticate' ] = exc.auth_header if getattr(exc, 'wait' , None ): headers['Retry-After' ] = '%d' % exc.wait if isinstance(exc.detail, (list, dict)): data = exc.detail else : data = {'detail' : exc.detail} set_rollback() errmsg = exc_map.get(exc.__class__.__name__, MagBaseException).get_message() return Response(errmsg, status=200 ) return None
抛出异常后,拦截它们,这里做统一的处理
列表页和新增实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from rest_framework.views import APIView, Request, Responsefrom .models import Employeefrom .serializers import EmpSerializerclass EmpsView (APIView) : """ 实现列表页get、新增post http://127.0.0.1:8000/emp/ """ def get (self, request) : emps = Employee.objects.all() return Response(EmpSerializer(emps, many=True ).data) def post (self, request) : serializer = EmpSerializer(data=request.data) serializer.is_valid(True ) serializer.save() return Response(serializer.data)
post测试数据
1 2 3 4 5 6 7 8 { "emp_no" : 10023 , "birth_date" : "2000-06-01" , "first_name" : "sam" , "last_name" : "lee" , "gender" : 1 , "hire_date" : "2020-08-24" }
详情页、修改和删除实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from rest_framework.views import APIView, Request, Responsefrom .models import Employeefrom .serializers import EmpSerializerclass EmpView (APIView) : """ 实现详情页get、修改put、删除delete http://127.0.0.1:8000/emp/10021 """ def get (self, request, pk:int) : obj = Employee.objects.get(pk=pk) return Response(EmpSerializer(obj).data) def put (self, request, pk:int) : obj = Employee.objects.get(pk=pk) serializer = EmpSerializer(obj, data=request.data) serializer.is_valid(True ) serializer.save() return Response(serializer.data, 201 ) def delete (self, request, pk:int) : Employee.objects.get(pk=pk).delete() return Response(status=204 )
PUT测试用Json
1 2 3 4 5 6 7 8 { "emp_no" : 10023 , "birth_date" : "2000-06-01" , "first_name" : "sam" , "last_name" : "lee" , "gender" : 2 , "hire_date" : "2019-08-24" }
完整参考代码 employee/views.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from rest_framework.views import APIView, Request, Responsefrom .models import Employeefrom .serializers import EmpSerializerclass EmpsView (APIView) : """ 实现列表页get、新增post http://127.0.0.1:8000/emp/ """ def get (self, request) : emps = Employee.objects.all() return Response(EmpSerializer(emps, many=True ).data) def post (self, request) : serializer = EmpSerializer(data=request.data) serializer.is_valid(True ) serializer.save() return Response(serializer.data) class EmpView (APIView) : """ 实现详情页get、修改put、删除delete http://127.0.0.1:8000/emp/10021 """ def get (self, request, pk:int) : obj = Employee.objects.get(pk=pk) return Response(EmpSerializer(obj).data) def put (self, request, pk:int) : obj = Employee.objects.get(pk=pk) serializer = EmpSerializer(obj, data=request.data) serializer.is_valid(True ) serializer.save() return Response(serializer.data, 201 ) def delete (self, request, pk:int) : Employee.objects.get(pk=pk).delete() return Response(status=204 )
employee/models.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from django.db import modelsclass Employee (models.Model) :class Gender (models.IntegerChoices) : MAN = 1 , '男' FEMALE = 2 , '女' class Meta : db_table = 'employees' verbose_name = '员工' emp_no = models.IntegerField(primary_key=True , verbose_name='工号' ) birth_date = models.DateField(verbose_name='生日' ) first_name = models.CharField(max_length=14 , verbose_name='名' ) last_name = models.CharField(max_length=16 , verbose_name='姓' ) gender = models.SmallIntegerField(verbose_name='性别' , choices=Gender.choices) hire_date = models.DateField() class Salary (models.Model) : class Meta : db_table = "salaries" 键 emp_no = models.ForeignKey(Employee, on_delete=models.CASCADE,db_column='emp_no' , related_name='salaries' ) from_date = models.DateField() salary = models.IntegerField(verbose_name='工资' ) to_date = models.DateField()
employee/serializers.py
1 2 3 4 5 6 7 8 9 10 11 12 from rest_framework import serializersfrom .models import Employee, Salaryclass SalarySerializer (serializers.ModelSerializer) : class Meta : model = Salary fields = '__all__' class EmpSerializer (serializers.ModelSerializer) : class Meta : model = Employee fields = '__all__'
通用视图 APIView是较为底层的封装,给我们的感觉,主要是对请求对象的封装,为查询字符串、提交的Json数据提供方便的属性等。
首先,EmpsView、EmpView的代码具有普遍性,其它对象增删改查也差不多。
其次,能否实现更加灵活的功能?有些需要列表页,有些需要详情页,有些则需要修改,有些需要新增,有些需要删除的功能,而能灵活做到这一点的可以是Mixin技术。
能否进一步封装,且做到自由组合?这就是GenericAPIView,它派生自APIView。
参考:https://www.django-rest-framework.org/api-guide/generic-views/#genericapiview
它只提供了
serializer_class,类属性,表示序列化类型,必须指定 或覆盖get_serializer_class()
get_serializer_class()返回值才是真正的被使用的序列化类,默认是serializer_class。如有必要,覆盖
queryset,类属性,默认为None,必须指定 或者覆盖get_queryset()
搜索单个对象是按照某些字段搜索,需要提供某些参数,也就是在URL conf中定义的使用关键字传参注入到方法中的参数
lookup_field,其默认值为’pk’,该类属性一般不需要修改
lookup_url_kwarg默认None,如果为None就使用lookup_field,如果不是’pk’,建议一定要设置
rest_framework.generics.GenericAPIView.get_object中有lookup_url_kwarg =self.lookup_url_kwarg or self.lookup_field
1 2 3 4 5 path('<int:pk>' , EmpView.as_view()) class EmpView (GenericAPIView) : def get (self, request:Request, pk:int) : pass
get_queryset(),其内部使用queryset类属性。Mixin里面查数据集,调用都是get_queryset方法。如有必要,覆盖
get_object(),详情页使用,其内部使用了get_queryset方法。Mixin里面获取单个对象调用它。如有必要,覆盖
简单讲,它定义了序列化、查询、分页功能接口。
注意:GenericAPIView不能增删改查,增删改查需要Mixin其他类。
Mixins 参考:https://www.django-rest-framework.org/api-guide/generic-views/#mixins
以下是孤立的功能Mixin类,需要和GenericAPIView类组合
ListModelMixin,list方法,列出所有数据,成功返回200。可以分页
CreateModelMixin,create方法,创建并保存一个对象,成功返回201,失败返回400
RetrieveModelMixin,retrieve方法,取回一个对象,成功返回200,失败返回404
UpdateModelMixin,update方法,更新并保存一个对象,成功返回200,失败返回400
DestroyModelMixin,destroy方法,对已存在对象进行删除,成功返回204,失败返回404
仅仅使用GenericAPIView不能简化什么代码,因为在EmpsView、EmpView中,写的最多的就是get、
put、post、delete方法,省略方法也是目标。当然,派生自GenericAPIView后,不要忘了指定queryset和serializer_class。
下面就利用GenericAPIView和Mixins重构View代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 from .models import Employeefrom .serializers import EmpSerializerfrom rest_framework.generics import GenericAPIViewfrom rest_framework.mixins import ( ListModelMixin, CreateModelMixin, RetrieveModelMixin, UpdateModelMixin, DestroyModelMixin ) class EmpsView (ListModelMixin, CreateModelMixin, GenericAPIView) : """ 实现列表页get、新增post http://127.0.0.1:8000/emp/ """ queryset = Employee.objects.all() serializer_class = EmpSerializer get = ListModelMixin.list post = CreateModelMixin.create class EmpView (RetrieveModelMixin, UpdateModelMixin, DestroyModelMixin, GenericAPIView) : """ 实现详情页get、修改put、删除delete http://127.0.0.1:8000/emp/10021 """ queryset = Employee.objects.all() serializer_class = EmpSerializer get = RetrieveModelMixin.retrieve put = UpdateModelMixin.update delete = DestroyModelMixin.destroy patch = UpdateModelMixin.partial_update
利用了写好的Mixin省掉了大量的代码。
能把上面代码中的get、post、put、delete方法也能简化掉吗?可以,DRF替你写好了
Concrete视图类 Concrete View类是由GenericAPIView和诸多Mixin类构成的子类。
Concrete具体的,也指混凝土,可以认为就是用泛型类GenericAPIView和各种Mixin类混合浇筑成的现成的、具体的,直接可以用的类。
Concrete View Class,就简称CVS
如果不需要自定义的话,可以考虑使用这些提前定义好的通用的View类。
列表页View
继承
方法
功能
CreateAPIView
GenericAPIView、CreateModelMixin
post
列表页新增对象功能
ListAPIView
GenericAPIView、ListModelMixin
get
获得列表页内容
ListCreateAPIView GenericAPIView、ListModelMixin、CreateModelMixin
get、post
完整列表页功能
RetrieveAPIView
GenericAPIView、RetrieveModelMixin
get
获取单个对象
UpdateAPIView
GenericAPIView、UpdateModelMixin
get、put
修改单个对象
DestroyAPIView
GenericAPIView、DestroyModelMixin
delete
删除单个对象
RetrieveUpdateDestroyAPIView
GenericAPIView、RetrieveModelMixin,、UpdateModelMixin、DestroyModelMixin
get、put、patch、 delete
详情页 查、 改、删 功能
RetrieveUpdateAPIView
GenericAPIView、RetrieveModelMixin、UpdateModelMixin
get、 put、 patch
RetrieveDestroyAPIView
GenericAPIView、RetrieveModelMixin、DestroyModelMixin
get、 delete
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from .models import Employeefrom .serializers import EmpSerializerfrom rest_framework.generics import ListCreateAPIView,RetrieveUpdateDestroyAPIView class EmpsView (ListCreateAPIView) : """ 实现列表页get、新增post http://127.0.0.1:8000/emp/ """ queryset = Employee.objects.all() serializer_class = EmpSerializer class EmpView (RetrieveUpdateDestroyAPIView) : """ 实现详情页get、修改put、删除delete http://127.0.0.1:8000/emp/10021 """ queryset = Employee.objects.all() serializer_class = EmpSerializer
分页 参考:https://www.django-rest-framework.org/api-guide/pagination/#setting-the-pagination-style
全局配置 1 2 3 4 REST_FRAMEWORK = { 'DEFAULT_PAGINATION_CLASS' :'rest_framework.pagination.PageNumberPagination' , 'PAGE_SIZE' : 10 }
测试 http://127.0.0.1:8000/emp/ ,分页返回数据了。 测试 http://127.0.0.1:8000/emp/?page=3,返回了第3页。
自定义分页类 测试http://127.0.0.1:8000/emp/?page=3&page_size=2,page_size似乎没有用,为什么?因为安全, 默认不接受客户端发来的参数。通过page_size_query_param设置类属性来接收浏览器发来的参数的。
工具包下面创建类 utils.paginations.PageNumberPagination ,代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from rest_framework import paginationclass PageNumberPagination (pagination.PageNumberPagination) : page_size_query_param = 'size' page_size = 4 max_page_size = 8 from .models import Employeefrom .serializers import EmpSerializerfrom rest_framework.generics import ListCreateAPIView,RetrieveUpdateDestroyAPIViewfrom utils.paginations import PageNumberPaginationclass EmpsView (ListCreateAPIView) : """ 实现列表页get、新增post http://127.0.0.1:8000/emp/ """ queryset = Employee.objects.all() serializer_class = EmpSerializer pagination_class = PageNumberPagination class EmpView (RetrieveUpdateDestroyAPIView) : """ 实现详情页get、修改put、删除delete http://127.0.0.1:8000/emp/10021 """ queryset = Employee.objects.all() serializer_class = EmpSerializer
测试 http://127.0.0.1:8000/emp/ 、http://127.0.0.1:8000/emp/?size=2
CVS已经很方便了,已经简化到用列表页、详情页2个类配置一下就行了。但是,可以看到它们也有重复 的地方,是否还可以简化?
这就需要使用视图集ViewSet。
视图集 参考:https://www.django-rest-framework.org/api-guide/viewsets/
视图集类关系
类
继承
ViewSet
ViewSetMixin、APIView
不提供操作,一般不用
重写了 as_view,使用 actions 字典建立
GenericViewSet
ViewSetMixin、GenericAPIView
具有 get_object, get_queryset,但是没有提供增删改查方法
ModelViewSet ListModelMixin、CreateModelMixin、RetrieveModelMixin、UpdateModelMixin、DestroyModelMixin、GenericViewSet
在 GenericViewSet 和 Mixins 基础上,提供了list()、create()、retrieve()、 update()、destroy()、partial_update()
ReadOnlyModelViewSet ListModelMixin、RetrieveModelMixin、GenericAPIView
list()、retrieve()
ViewSetMixin.as_view(cls, actions=None, **initkwargs) 通过actions字典来解决method和handler映射,例如ViewSet.as_view({'get': 'list', 'post': 'create'})2个get方法可以通过路径配置不一样解决。
ModelViewSet
5个Mixin提供了方法,例如list、retrieve、create等
ViewSetMixin解决了类二合一路由问题
要指定action,指明request method和handler映射关系
GenericAPIView
要指定queryset、serializer_class
视图集应用 视图层代码 注意:一定要在路由中配置一下actions
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from .models import Employeefrom .serializers import EmpSerializerfrom rest_framework.viewsets import ModelViewSetclass EmpViewSet (ModelViewSet) : queryset = Employee.objects.all() serializer_class = EmpSerializer
路由配置 employee/urls.py 指定列表页、详情页的action,建立到handler的映射
1 2 3 4 5 6 urlpatterns = [ path('' , EmpViewSet.as_view({'get' :'list' , 'post' :'create' })), path('<int:pk>/' , EmpViewSet.as_view({ 'get' : 'retrieve' , 'put' : 'update' , 'delete' : 'destroy' })), ]
路由器
视图集的action配置很固定,能否也简化? 下面就以简单路由器类实现路由的简化。
SimpleRouter注册需要2个参数
prefix:前缀,可以为空串
viewset:提供视图集
最终返回路由配置的列表
employee/urls.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from django.urls import pathfrom .views import EmpViewSetfrom rest_framework.routers import SimpleRouterrouter = SimpleRouter() router.register('' , EmpViewSet) urlpatterns = router.urls print('+' * 30 ) print(urlpatterns) print('+' * 30 ) <URLPattern'^$' [name='employee-list' ]> <URLPattern'^(?P<pk>[^/.]+)/$' [name='employee-detail' ]>